概念
SQL (Structured Query Language):语句由子句(clause)构成,用于取回和更新数据库中的数据,可与数据库程序协同工作。这样的数据库管理系统(DBMS)包括但不限于MS Access、DB2、Informix、MySQL、Oracle。
数据库 (database):保存有组织的数据的容器,通常是一个/一组文件,通过为应用程序提供接口达到读写数据的目的。种类分为层次模型(上下级)、网状模型(节点互相连接)与关系模型(二维行列表;常见且泛用)。
模式 (schema):表述数据库的内容、其中表的布局关系及特性。
数据类型 (datatype):所允许的数据类型,每个表列都有对应的数据类型,规定该列所存储的数据。另外需要注意,一些高级数据类型在不同的DBMS中并不兼容。不同DBMS使用不同函数来转换数据类型(例:MySQL使用CONVERT(),PostgreSQL使用CAST(),Access和Oracle使用多个函数)
主键 (primary key):用来标识表中每一行的列,也会出现联合主键的情况(例:id_num, id_type),常见类型包括自增整数类型和GUID/UUID类型。主键不能重复、修改或更新,也不应该允许NULL的出现。
外键 (foreign key):不同于主键的标识列,用来确定当前表在其它表中对应的记录,可实现一对多、多对多和一对一的关系。外键既可通过数据库来约束,也可仅依靠应用程序的逻辑来保证。
索引 (index):关系数据库中对某一列或多个列的值进行预排序的数据结构,使用它可以让数据库系统不必扫描整个表,而是直接定位到符合条件的记录,大大加快查询速度。可加入唯一索引ADD UNIQUE INDEX或对某一列添加唯一约束ADD CONSTANT,还可对一张表创建多个索引(例:ADD INDEX idx_ns (name, score);)或强制索引(FORCE INDEX)。列中值重复度越低索引效率越高,因此对主键的索引效率最高。索引的优点是提高了查询效率,缺点是在插入、更新和删除记录时,需要同时修改索引,因此修改越多,删除记录的速度就越慢。
字段 (field):可与列互换使用,但此术语通常与计算字段而非数据库列一起使用。若要拼接(concatenate)字段,在不同DBMS中可使用“+”或“||”进行。如SELECT RTRIM(vend_name) + ' (' + RTRIM(vend_country) + ')' FROM Vendors的输出示例为Furball Inc. (USA)。
可移植 (portable):编写的代码可以在多个系统上运行。
可伸缩 (scale): 能适应不断增加的工作量而不失败。设计良好的数据库或应用程序,被称为可伸缩性好 (scale well)。
笛卡儿积 (cartesian product):由没有联结条件的表关系,返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。返回笛卡儿积的联结,有时也称叉联结 (cross join)。
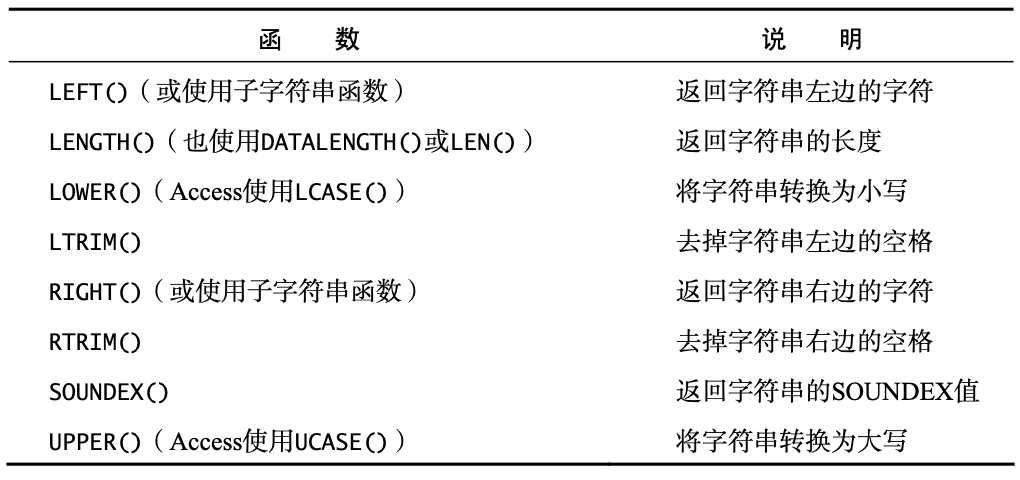
函数 (function):一些常用的文本、数值处理函数和聚集函数 (aggregate function)。


COUNT(*)会计入NULL值MySQL
这个板块可能单开一篇来存放更详细笔记,这里留下一些资源,暂时不做过多记录。
MySQL Cheat Sheet.pdf -> https://www.datacamp.com/cheat-sheet/my-sql-basics-cheat-sheet
参考手册 -> https://www.w3ccoo.com/sql/sql_ref_mysql.html
快速教程 -> https://www.datacamp.com/tutorial/my-sql-tutorial
语法示例
可在此处以给定数据集进行在线练习。
SELECT DISTINCT: SELECT DISTINCT City FROM Nation;— 查询不同值,不能用于计算或表达式,指定列名的情况下DISTINCT只能用于COUNT()而不能用于COUNT(*)。若SELECT不加FROM字句,则可以简单访问和处理表达式(例:SELECT 1+1返回2)
Alias: SELECT City, Language AS Lang FROM Nation;— 即导出列(derived column);AS在许多DBMS中通常是可选的,Oracle中没有AS,但大多场合下仍然推荐使用
WHERE: SELECT * FROM Nation WHERE (City = 'Berlin' OR id != '34');— 推荐在使用AND/OR操作符的WHERE字句中添加圆括号,以便消歧义;此外不相等“<>”和“!=”可用来替代NOT操作符
HAVING: SELECT * FROM Nation GROUP BY Lang Having City > 3 — 查询覆盖城市超过3个的语言。此外,HAVING子句可以筛选分组后的各组数据,支持所有WHERE操作符,区别在于WHERE无法与聚合函数一起使用
NULL: SELECT * FROM Customers WHERE Area IS NOT NULL;
GROUP BY: SELECT COUNT(VisitId), Country FROM Visitor WHERE id>50 GROUP BY Country ORDER BY COUNT(VisitId) DESC;— 列出每个国家的游客数量,按游客最多的国家排序;默认排序为升序ASC
ORDER BY: SELECT * FROM Nation ORDER BY Area, City, DESC;— order by area, and then by city, descending
CASE: SELECT Name, Area, City, Lang FROM Nation ORDER BY (CASE WHEN City IS NULL THEN Name ELSE City END); — 当城市为空,按国家名排序;WHEN…THEN语句可有多个,相当于If-Else语句
SELECT INTO: SELECT City, Lang INTO newtb [IN externaldb] FROM Nation WHERE id < 100; — 将指定数据从一个表复制到另一新表
INSERT: INSERT INTO Nation (Name, Area, Lang, City) VALUES ('Norway','Europe','Norwegian','Oslo');— 添加国家Norway,若记录已经存在,就更新该记录
UPDATE: UPDATE Nation SET City = 'Oslo', Name = 'Norway' WHERE id = 32;— entire column will be changed if there’s no WHERE condition
DELETE: DELETE FROM Nation WHERE City = 'Washington DC';
函数使用: SELECT MAX(Price) AS MaxPrice, MIN(Price) AS MinPrice FROM Nation;— 此外提取部分字符串使用SUBSTR()-Oracle, SUBSTRING()-MySQL, MID()-Access;区当前日期使用CURDATE()-MySQL, SYSDATE-Oracle, NOW()-Access
聚合查询: SELECT COUNT(*) FROM Products WHERE Price = 18;— 返回Price值设置为18的数量,包括NULL值
多表查询: SELECT s.id sid, s.gender, c.id cid FROM students s, classes c WHERE s.gender = 'M' AND c.id = 1;
分页查询:SELECT * FROM Nation LIMIT 3 OFFESET 6;— 每页三行,从第三列开始查询。若不设OFFSET则默认从第一页开始,即OFFSET=0。OFFSET即便超过最大值也不会报错,而是得到空的结果集。MySQL中LIMIT 1 OFFSET 2还可以简写成LIMIT 1, 2。要注意的是,使用LIMIT <M> OFFSET <N>分页时,随着N越来越大,查询效率也会越来越低。
LEFT JOIN: SELECT * FROM Orders LEFT JOIN Nation ON Orders.NationId = Nation.id;— 使用Orders的全部记录,加上Nation表所有匹配项;RIGHT JOIN反之。此外由于联结消耗资源,因此注意不做非必要的连结。
INNER JOIN: SELECT * FROM Orders INNER JOIN Nation ON Orders.NationId = Nation.id;— 从两个表中选择所有记录,两个表中都有匹配项
IN: SELECT * FROM Nation WHERE City NOT IN ('Norway', 'France');— IN操作符一般比OR更快,也可包含其它SELECT字句
BETWEEN: SELECT * FROM Nation WHERE City NOT BETWEEN 'China, Ireland'; — 字母顺序在两者之间,数值类型同理
LIKE: SELECT * FROM Nation WHERE City LIKE 'a%'— a开头 ('a%'), a结尾 ('%a'), a开头b结尾 ('a%b'), 不含a (NOT LIKE '%a%')
Wildcards: 通配符区分大小写,但忌滥用,将其用在搜索模式开始处会最慢。下面展示通配符例子。
第一个字母为“a”或“c”或“s” (LIKE '[acs]%'), 第二个字母为“a”并以“k结尾” ('_a%k' _代表单个字符), a-f任意字符开头 ('[a-f]%' -代表一系列字符), 第一个字母不是“a”或“A”或“f” ('[^aAf]%' ^代表不在括号字符集内的字符), 以“a”开头且至少三个字符长('a_%_%')。
此外,Microsoft Access需要使用*而非%,!而非^。
添加数据库testDB: CREATE DATABASE testDB;
删除数据库testDB: DROP DATABASE testDB;— DROP TABLE可用于删除表
创建新表Persons: CREATE TABLE Persons ( PersonID int, LastName varchar(255), FirstName varchar(255), Address varchar(255), City varchar(255) );
删除表中所有数据: TRUNCATE TABLE Persons;
为表添加类型为DATE的“Birthday”列: ALTER TABLE Persons ADD Birthday DATE; — DROP COLUMN Birthday可用于删除此列
CREATE TABLE: CREATE TABLE tb1 SELECT * FROM Persons — 拍摄快照
写入查询结果集:
--创建成绩统计表
CREATE TABLE statistics (
id BIGINT NOT NULL AUTO_INCREMENT,
class_id BIGINT NOT NULL,
average DOUBLE NOT NULL,
PRIMARY KEY (id)
);
--写入各班平均成绩
INSERT INTO statistics (class_id, average)
SELECT class_id, AVG(score) FROM students GROUP BY class_id;
--输出
> SELECT * FROM statistics;
+----+----------+--------------+
| id | class_id | average |
+----+----------+--------------+
| 1 | 1 | 86.5 |
| 2 | 2 | 73.666666666 |
| 3 | 3 | 88.333333333 |
+----+----------+--------------+
3 rows in set (0.00 sec)